


今回は、配列のスライス処理について学んでいきます。スライス処理とは、配列から特定の範囲の要素を選択して取り出す操作を意味します。
この操作は機械学習において、データを適切な形式に整形する前処理でよく使用されます。前処理次第で、機械学習の効率性が大きく変わるため、重要な処理の一つです。
環境構築については、コチラの記事を参照してください。
スライスの使用用途
まず、スライスをどのような時に使用するのか説明します。
例えば、1000行(データポイント)と10列(特徴量)からなる、ある施設の来客者データがあるとします。
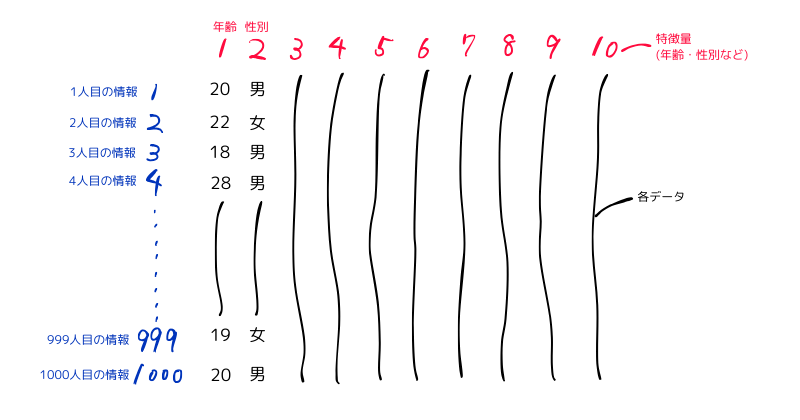
この中の全ての特徴量を使用したのでは機械学習として効率が悪くなったり、必要の無い情報がある場合、必要な情報のみに絞って機械学習を行います。このような特徴量選択は、データの次元を減らす(次元削減)、モデルの計算効率を改善する、または最も意味のある特徴量に基づいて予測精度を高めるために行われます。
例えば先ほどのデータで、年齢と性別のみに絞ってデータを整形します。ここで使用されるのがスライスです。

今回の場合、来客者の年代・性別のみに絞って、どのような人が多いのか精度の高い結果を得ることができます。
配列のスライス
Numpyのスライス構文は、標準のPython構文と同様で、コロン(:)にてスライスを行います。
x[start:stop:step]このような表記を行い、startはインデックスで指定、stopは何個目の要素かを指定します。またstart, stop, stepはそれぞれ省略することができ、省略した際のデフォルト値はstart=0, stop=その次元のサイズ, step=1となります。
例えば、x=[1, 2, 3, 4, 5, 6]という配列の場合、
x=[1, 2, 3, 4, 5, 6]
x1 = x[1:4:1]
print(x1)
## 結果:[2, 3, 4]この場合、インデックス1である要素”2″(start)から4個目の要素”4″(stop)までの要素を1つずつ(step)取得することになります。
1次元のスライス
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
という配列について、例を下記に示します。
・最初の5要素を取得
x1 = x[:5]
## 結果:0, 1, 2, 3, 4・インデックス5以降の要素を取得
x2 = x[5:]
## 結果:5, 6, 7, 8, 9・1つおきの要素を取得
x3 = [::2]
## 結果:0, 2, 4, 6, 8・インデックス1から、1つおきの要素を取得
x4 = [1::2]
## 結果:1, 3, 5, 7, 9多次元配列のスライス
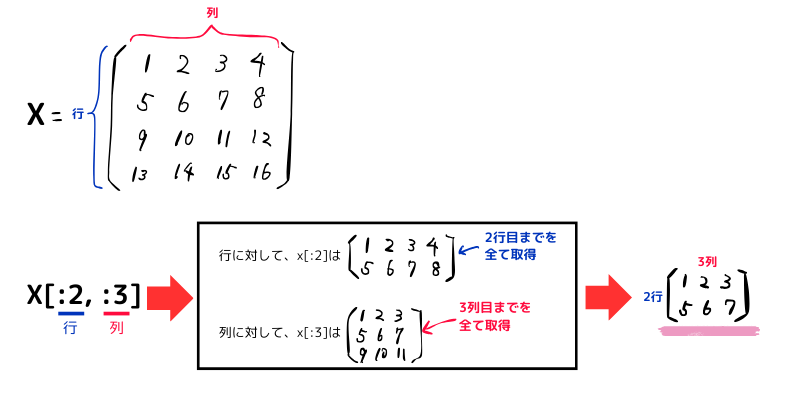
多次元のスライスは、複数のスライスをカンマ区切りで指定し、x[行, 列] の順序で記述します。
・対象の配列
x = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
])⚪️2行と3列を取得
x1 = x[:2, :3]
'''
結果:
[[1 2 3]
[5 6 7]]
'''下記図のように、“行”と”列”それぞれに対して1次元のスライスと同様に考えるとわかりやすいです。
多次元配列のスライスで最も使用される操作は、特定の行または列の抽出です。
これは、下記のように行または列のインデックスと、:(コロン)によって抽出できます。
:(コロン)のみを記述した場合、その行または列を全て取得します。
⚪️全ての行と、インデックス0の列を取得
x2 = [:, 0]
## 結果:[1 5 9 13]⚪️インデックス0の行と、全ての列を取得
x3 = [0, :]
## 結果:[1 2 3 4]まとめ
この記事では、機械学習におけるデータ前処理技術の中でも特に重要な配列のスライス処理について掘り下げました。スライス処理は、データセットを適切な形式に整形する上で不可欠です。効率的な機械学習モデルの訓練には、不要な情報を取り除き、必要な情報のみを特徴量として選択することが重要です。
本記事では、スライス処理の基礎から始め、1次元および多次元配列におけるスライスの応用までをカバーしました。簡単な構文x[start:stop:step]を用いることで、配列の任意のセクションを柔軟に操作できることが示されました。特に、多次元配列では、スライスを使用して特定の行や列を効率的に選択し、データ分析や機械学習モデルの入力として使用する方法について説明しました。
この技術の理解と適用は、機械学習におけるデータの前処理という複雑な段階を大きく簡略化し、モデルの性能を最大化するために必要なデータの選択と変換を容易にします。スライス処理の知識は、機械学習プロジェクトにおけるデータ操作の効率性と精度を高めるために不可欠です。


コメント